Построение запросов в sql. Примеры SQL запросов к базе данных MySQL. Сложные SQL запросы
Выборка данных из таблицы в SQL осуществляется с помощью следующей конструкции:
SELECT
*|
[AS
] FROM
[WHERE
[AND
]]
[GROUP BY | [HAVING
]]
[ORDER BY
[COLLATE
]
]
Раздел SELECT
→ Определить список выходных столбцов
Список выходных столбцов может быть указан несколькими способами:
. Указать символ *, обозначающий включение в результаты запроса всех колонок запроса в естественной последовательности.
. Перечислить в желательном порядке только нужные.
Пример: SELECT * FROM Customer
→ Включить вычисляемые столбцы
В качестве вычисляемых столбцов запроса могут выступать:
. Результаты простейших арифметических выражения (+, -, /, *_ или конкатенации строк (||).
. Результаты функций агрегирования COUNT(*)|{AVG|SUM|MAX|MIN|COUNT} (
)
Примечание
: В SQL Server дополнительно можно использовать оператор % — модуль (целый остаток от деления).
→ Включить константы
В качестве столбцов могут выступать константы числового и символьного типов.
Примечание : SELECT DISTINCT ‘Для ‘, SNum, Comm*100, ‘%’, SName FROM SalesPeople
→ Переименовать выходные столбцы
Вычисляемым, а также любым другим столбцам, при желании, можно присвоить уникальное имя с помощью ключевого слова AS: AS
Примечание : В SQL SERVER дать новое имя столбцу можно с помощью оператора присвоения =
→ Указать принцип обработки дублей строк
DISTINCT – запрещает появление строк-дублей в выходном множестве. Его можно задавать один раз для оператора SELECT. На практика первоначально формируется выходное множество, упорядочивается, а затем из него удаляются повторяющиеся значения. Обычно это занимает много времени и не следует этим злоупотреблять.
ALL (действует по умолчанию) – обеспечивает включение в результаты запроса и повторяющихся значений
→ Включить агрегатные функции
Функции агрегирования (функции над множествами, статистические или базовые) предназначены для вычисления некоторых значений для заданного множества строк. Используются следующие агрегатные функции:
. AVG|SUM(|) – подсчитывает среднее значение | сумму от или, возможно без учета дублей, игнорируя NULL.
. MIN|MAX() – находит максимальное | минимальное значение.
. COUNT(*) – подсчитывает число строк во множестве с учетом NULL значений | значений в столбце, игнорируя NULL значения, возможно без дублей.
Примечания по использованию
:
. Функции агрегирования нельзя вкладывать друг в друга.
. Из-за значений NULL выражение SUM(F1)-SUN(F2)Sum(F1-F2)
. Внутри функций агрегирования допустимы выражения AVG(Comm*100)
. Если в результате запроса не получено ни одной строки или все значения равны NULL, то функция COUNT возвращает 0, а другие – NULL.
. Функции AVG и SUM могут применяться только для числовых типов, данных в Interval, а остальные могут использоваться для любых типов данных.
. Функция COUNT возвращает целое число (типа Integer), а другие наследуют типы данных обрабатываемых значений, вследствие чего следует следить за точностью результата функции SUM (возможно переполнение) и масштабом функции AVG.
Примеры на агрегатные функции:
SELECT COUNT(*) FROM Customer
. SELECT COUNT(DISTINCT SNum) FROM Orders
. SELECT MAX(Amt+Binc) FROM Orders //Если Binc – дополнительное числовое поле в Orders
. SELECT AVG(Comm*100) FROM SalesPeople //Выражение внутри функции
→ Особенности промышленных серверов
В СУБД Oracle в разделе SELECT можно указывать дополнительные указания-подсказки (hints) (27 штук), влияющие на выбор типа оптимизатора запросов и его работу.
SELECT /*+ ALL_ROWS */ FROM Orders… //наилучшая производительность
В СУБД SQL Server
:
] – задает количество или процент считываемых строк. При одинаковых последних значениях возможно считывание всех таких строк и общее число может быть больше указанного.
DECLARE @p AS Int
SELECT @p=10
SELECT TOP(@p) WITH TIES * FROM Orders
Раздел FROM
Этот раздел является обязательным и позволяет:
→ Указать имена исходных таблиц
В разделе FROM указываются имена таблиц и/или представлений, из которых будут извлекаться данные. Причем одна и та же таблица может несколько раз входить в этот раздел.
Примечание: В СУБД Oracle можно выбирать строки и из снимков (Snapshot).
→ Указать псевдонимы таблиц
Под псевдонимом таблицы понимается дополнительный, обычно краткий идентификатор, указываемый через пробел после имени таблицы/представления.
Пример: Customer C
→ Указать вариант внешнего объединения таблиц
Если в разделе FROM указано несколько таблиц, то все они неявно считаются внешними соединениями. В стандарте предусмотрены следующие основные виды соединений таблиц:
1) Перекрестное соединение
CROSS JOIN — определяются все возможные сочетания пар строк по одной для каждой строки каждой из объединяемых таблиц. Эквивалентно картезианскому соединению. Иногда называет декартовым произведением.
2) Естественное соединение
JOIN — определяются только те строки таблиц А и B, в которых значения столбцов одинаковы. Называют не совсем полноценным эквисоединением. Это автоматическое соединение по нескольким столбцам со всеми одинаковыми именами (join over).
3) Соединение объединением
UNION JOIN — определяются только те строки каждой из таблиц, для которых совпадения не были установлены. Столбцы из другой таблицы заполняются значениями NULL. Отметим, что соединение UNION и оператор UNIUN – это не одно и то же. Соединение противоположно соединению типа INNER.
4) Объединение посредством предиката
JOIN ON — фильтрует строки. Предикат может содержать подзапросы.
5) Объединение посредством имен столбцов
JOIN USING() – определяет соединение только по указанным столбцам, в то время как NATURAL – автоматически по всем одноименным.
Типы соединений
представляет собой один из аргументов: INNER
|{LEFT|RIGHT|FULL}
. INNER
– включает строки, в которых есть столбцы с совпадающими данными объединяемых таблиц. Используется по умолчанию.
. LEFT
– включает все строки таблицы А (левая таблица) и все совпадающие значения из таблицы B. Столбцы несовпадающих строки заполняются NULL-значениями.
. RIGHT
– включает все строки таблицы B (правая таблица) и все совпадающие значения таблицы А. обратный вариант для левого объединения.
. FULL
– включает все строки обеих таблиц. Столбцы совпадающих строк заполнены реальными значениями, а несовпадающих строк – NULL-значениями.
. OUTER (внешний)
– уточняющее слово, означающее, что несовпадающие строки из ведущей таблицы включаются вместе с совпадающими.
Примеры на внешнее объединение:
SELECT * FROM SalesPeople INNER JOIN Customer ON SalesPeople.City=Customer.City
. SELECT * FROM Customer LEFT OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
. SELECT * FROM Customer FULL OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
Картезианские соединения и самообъединения
. Если при включении нескольких таблиц не используются те или иные варианты соединения таблиц, то такие соединения называются картезианскими. Они используются для получения строк из двух различных таблиц. Тогда например, при соединении двух таблиц, каждая из которых содержит по 20 строк, итоговая таблица будет содержать 100 строк – каждая из строк одной таблицы с каждой из строк другой таблицы. SELECT * FROM Customer, Orders.
. Соединения одинаковых таблиц называют самообъединением (self-join).
Раздел WHERE
1. Создание внутренних соединений
Связь между таблицами осуществляют с помощью операторов сравнения, а в список выходных столбцов включают квалификационные имена для одноименных столбцов из исходных таблиц.
Основные виды соединений:
. Эквисоединения
– это соединения таблиц, основанные на равенствах. Связь между таблицами по ключевым столбцам обеспечивает ссылочную целостность. Если при соединении используются первичный и внешний ключ то всегда существует отношение «один-ко-многим» (предок/потомок).
. Тэта-соединения
– это такое соединение, когда в качестве оператора сравнения применяется неравенство (, >=, Примечания по SQL Server
В SQL Server левое, правое и полное соединение можно задать в разделе WHERE с помощью [*]=[*]. Фактически реализуется внешнее соединение, которое у других СУБД реализуется в разделе FROM.
Примеры внутренних соединений
SELECT C.CName, S.SName, S.City FROM SalesPeople S, Customer C WHERE S.City=C.City
SELECT SName, CName FROM SalesPeople, Customer WHERE SName
2. Фильтрация строк выходного множества
Раздел WHERE позволяет также определить, т.е. логическое условие, которое может быть либо истинным, либо ложным. Кроме того, одно или оба сравниваемых значения в предикате могут быть равны NULL, тогда результат сравнения может быть равен UNKNOWN. Оператор SELECT извлекает только те строки из таблиц, для которых имеет значение TRUE, исключая строки, для которых он равен FALSE или UNKNOWN.
ПРОСТЫЕ ВЫБОРКИ ДАННЫХ
Предположим, что реляционная база данных, состоящая из одной или нескольких таблиц, создана и вы к ней уже подключились. В этом случае типичной практической задачей является получение (извлечение) нужных данных. Например, может потребоваться просто просмотреть все содержимое какой-либо таблицы из базы данных или некоторых ее полей. При этом возможно, вы захотите получить не все записи, а лишь те, которые удовлетворяют заданным условиям. Однако чаще возникает более интересная и сложная задача извлечения данных сразу из нескольких таблиц. Данные из двух и более таблиц необходимо скомпоновать в одну таблицу, чтобы представить ее для обозрения, анализа или последующей обработки. Язык SQL предоставляет для этого широкие возможности, которые мы и рассмотрим.
В результате выполнения выражения на языке SQL (SQL-выражения) создается таблица, которая либо содержит запрошенные данные, либо пуста, если данных, соответствующих запросу, не нашлось. Эта таблица, называемая еще результатной, существует только во время сеанса работы с базой данных и не присоединяется к числу таблиц, входящих в базу данных. Иначе говоря, она не хранится на жестком диске компьютера подобно исходным таблицам базы данных, и поэтому ее еще называют виртуальной.
Выборка данных из нескольких таблиц, их обработка, а также использование подзапросов (запросов, которые нужны в качестве промежуточных для получения окончательного результата) относятся к теме сложных запросов. Здесь мы остановимся на задаче выборки данных из одной таблицы при относительно простых условиях отбора, группировки и сортировки записей. Тем не менее, операторы SQL, применяемые в простых запросах на выборку данных, используются и в сложных запросах, направленных не только на получение, но и на изменение данных. Начните с простого, чтобы потом было легко понять сложное. Материал данной главы относится к фундаментальным темам SQL, хотя многие пользователи баз данных могут им и ограничиться. Последнее вполне вероятно, поскольку материал этой главы сам по себе исключительно практичен.
Все SQL-выражения, предназначенные для выборки данных из существующих таблиц базы данных, начинаются с ключевого слова (оператора) SELECT (выбрать). Для уточнения запроса служат дополнительные операторы, такие как FROM (из), WHERE (где) и др. Сейчас важно понять и запомнить, что результатом выполнения запроса, сформулированного в виде SQL-выражения, является таблица, содержащая запрошенные данные. Эта таблица виртуальна в том смысле, что только представляет результаты запроса и не принадлежит к базе данных. SQL позволяет изменять существующую базу данных - создавать и добавлять к ней новые таблицы, а также модифицировать и удалять уже существующие.
Основное SQL-выражение для выборки данных
Чтобы выбрать из таблицы базы данных требуемые записи, следует, по крайней мере, указать столбцы и имя этой таблицы. Это требование было бы естественно сформулировать так:
ВЫБРАТЬ такие-то столбцы ИЗ такой-то таблицы;
Разумеется, вам может потребоваться выбрать не все записи таблицы, а лишь те, которые отвечают некоторому условию. На практике именно так и бывает. Отложим пока рассмотрение формирования условий отбора записей, а сконцентрируем внимание на выборке всех записей из заданной таблицы. SQL-запрос к базе данных, результатом которого является таблица, полученная из указанной в запросе, но отличающаяся от нее тем, что содержит лишь указанные столбцы, выглядит так:
SELECT списокСтолбцов FROM список Таблиц;
Операторы SELECT (выбрать) и FROM (из) в SQL-выражении, определяющем выборку данных, являются обязательными, т. е. ни один из них нельзя пропустить. SQL-выражение, содержащее только эти операторы, является основным выражением, определяющим запрос к базе данных на выборку данных. В результате выполнения этого запроса создается виртуальная таблица, содержащая указанные столбцы и все записи исходной таблицы.
Оператор SELECT осуществляет проекцию отношения, указанного в выражении FROM, на заданное множество атрибутов (столбцов), указанное в выражении SELECT.
В выражении FROM указывается список имен таблиц базы данных, из которых требуется выбрать данные. В простейшем случае списокТаблиц содержит лишь одно имя таблицы. Если же таблиц несколько, то их имена в списке разделяются запятыми. Если в выражении FROM указано более одной таблицы, то результатная таблица получается из декартового произведения перечисленных в списке таблиц. Иногда это используется для специальных целей, но чаще всего в выражении FROM указывается только одна таблица.
Список столбцов - это перечень имен столбцов, разделенных запятой, как они определены в таблице, указанной в выражении FROM. Разумеется, можно указать все или только некоторые столбцы. Если вы хотите получить все столбцы таблицы, то вместо списка столбцов достаточно указать символ (*). Если в выражении FROM указано несколько таблиц, то в выражении SELECT имена столбцов должны содержать префиксы, указывающие, к какой именно таблице они относятся. Префикс отделяется от имени столбца точкой. Например, выражение Клиенты.Адрес означает столбец Адрес из таблицы Клиенты.
Тривиальный запрос, возвращающий все данные (все столбцы и все записи) из одной таблицы, формулируется так:
SELECT * FROM имяТаблицы ;
Основное SQL-выражение может быть дополнено другими операторами, уточняющими запрос. Чаще всего употребляется оператор WHERE (где), с помощью которого можно задать условие выборки записей (строк таблицы). Таким образом, если выражение SELECT задает столбцы таблицы, указанной в операторе FROM, то выражение WHERE определяет записи (строки) из этой таблицы. Выражение, определяющее запрос на выборку данных, находящихся в некоторой таблице, имеет следующий вид:
SELECT * FROM имяТаблицы WHERE условиеПоиска ;
Условие, указанное в выражении WHERE, принимает одно из двух логических значений: true (ИСТИНА) или false (ЛОЖЬ). Другими словами, это логическое выражение. При обработке запроса условие проверяется для каждой записи таблицы. Если оно истинно для данной записи, то она выбирается и будет представлена в результатной таблице. В противном случае запись не выбирается и в результатную таблицу не попадает. Если выражение WHERE не указано в SQL-выражении, то результатная таблица будет содержать все записи из таблицы, заданной в выражении FROM. Таким образом, выражение WHERE определяет фильтр записей. Фильтр что-то пропускает в результатную таблицу, а что-то отбрасывает.
Фильтр - одно из основных понятий в области работы с базами данных. В литературе иногда можно встретить различные его трактовки. Так, "отфильтровать записи" может означать "получить записи", а может наоборот - "отбраковать записи". Здесь понятия "отфильтровать", "пропустить через фильтр" или "наложить фильтр" всегда означают "выбрать записи, удовлетворяющие условию фильтра".
Сразу за оператором SELECT до списка столбцов можно применять ключевые слова ALL (все) и DISTINCT (отличающиеся), которые указывают, какие записи представлять в результатной таблице. Если эти ключевые слова не используются, то подразумевается, что следует выбрать все записи, что также соответствует применению ключевого слова ALL. В случае использования DISTINCT в результатной таблице представляются только уникальные записи. При этом если в исходной таблице находятся несколько идентичных записей, то из них выбирается только первая.
Примечание
В Microsoft Access кроме ключевых слов ALL и DISTINCT после SELECT можно использовать ключевое слово ТОР с дополнительными параметрами. Выражение ТОР n требует, чтобы в выборку данных попали только первые n записей, удовлетворяющих заданному условию запроса. Это ограничение условия поиска нужных записей, формулируемого в выражении WHERE. Если исходная таблица очень большая, то DISTINCT может ускорить получение ответа.
В Access можно использовать и выражение ТОР n PERCENT, чтобы указать, что n выражается в процентах от общего количества записей. Не трудно понять, что использование такого выражения направлено не на ускорение поиска, а на получение таблицы, избавленной от лишних данных.
Заголовки столбцов в результатной таблице можно переопределить по своему усмотрению, назначив для них так называемые псевдонимы . Для этого в списке столбцов после соответствующего столбца следует написать выражение вида: AS заголовок_столбца
Например:
SELECT ClientName AS Клиент, Address AS Адрес FROM Клиенты;
Псевдонимы также можно задать и для каждой таблицы после ключевого слова FROM. Для этого достаточно указать псевдоним через пробел сразу после имени соответствующей таблицы. Псевдонимы таблиц, более короткие, чем их имена, удобно использовать в сложных запросах. Например:
SELECT Т1.Имя, Т2.Адрес FROM Клиенты Т1, Контакты Т2;
Уточнения запроса
Основное SQL-выражение для выборки данных имеет вид:
SELECT списокСтолбцов FROM списокТаблиц;
Такой запрос возвращает таблицу, полученную из указанной в операторе FROM путем выделения в ней только тех столбцов, которые определены в операторе SELECT. Для выделения требуемых записей (строк) исходной таблицы используется выражение, следующее за ключевым словом (оператором) WHERE. Оператор WHERE является наиболее часто используемым, хотя и не обязательным в SQL-выражении. Именно из-за популярности его можно считать основным компонентом SQL-выражения. Кроме WHERE, в SQL-выражениях используются и другие операторы, позволяющие уточнить запрос.
Для уточнения запроса на выборку данных служит ряд дополнительных операторов:
· WHERE (где) - указывает записи, которые должны войти в результатную таблицу (фильтр записей);
· GROUP BY (группировать по) - группирует записи по значениям определенных столбцов;
· HAVING (имеющие, при условии) - указывает группы записей, которые должны войти в результатную таблицу (фильтр групп);
· ORDER BY (сортировать по) - сортирует (упорядочивает) записи.
Эти операторы не являются обязательными. Их можно совсем не использовать, или использовать лишь некоторые из них, или все сразу. Если применяются несколько операторов, то в SQL-выражении они используются в указанном в списке порядке. Таким образом, запрос данных из таблицы с применением всех перечисленных операторов уточнения запроса имеет следующий вид:
SELECT списокСтолбцов FROM имяТаблицы
WHERE условиеПоиска
GROUP BY столбецГруппировки
HAVING условиеПоиска
ORDER BY условиеСортировки;
Порядок перечисления операторов в SQL-выражении не совпадает с порядком их выполнения. Однако знание порядка выполнения операторов поможет вам избежать многих недоразумений. Итак, перечисленные операторы SQL-выражения выполняются в следующем порядке, передавая друг другу результат в виде таблицы:
1. FROM - выбирает таблицу из базы данных; если указано несколько таблиц, то выполняется их декартово произведение и результирующая таблица передается для обработки следующему оператору.
2. WHERE - из таблицы выбираются записи, отвечающие условию поиска, и отбрасываются все остальные.
3. GROUP BY - создаются группы записей, отобранных с помощью оператора WHERE (если он присутствует в SQL-выражении); каждая группа соответствует какому-нибудь значению столбца группирования. Столбец группирования может быть любым столбцом таблицы, заданной в операторе from, а не только тем, который указан в SELECT.
4. HAVING - обрабатывает каждую из созданных групп записей, оставляя только те из них, которые удовлетворяют условию поиска; этот оператор используется только вместе с оператором GROUP BY.
5. SELECT - выбирает из таблицы, полученной в результате применения перечисленных операторов, только указанные столбцы.
6. ORDER BY - сортирует записи таблицы. При этом в условии сортировки можно обращаться лишь к тем столбцам, которые указаны в операторе SELECT.
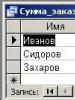
Допустим, среди таблиц вашей базы данных имеется таблица Клиенты, которая содержит столбцы с именами: имя, Адрес, Сумма_заказа и, возможно, какие-то другие. Семантика этой таблицы тривиальна. В ней фиксируются данные о клиентах и денежные суммы, которые они заплатили вашей фирме, пользуясь ее услугами.
Рис. 1. Таблица Клиенты
Предположим, нас интересуют не все данные этой таблицы, а только те, которые касаются клиентов, заплативших фирме более 500 (сейчас не важно, в какой валюте производились оплаты). Точнее, нам нужны имена и адреса клиентов, которые заплатили фирме более 500 денежных единиц. Таким образом, нам необходимо получить не все, что содержится в таблице Клиенты, а лишь некоторую ее часть, как по столбцам, так и по записям. Для этой цели подойдет следующее SQL-выражение:
WHERE Сумма_заказа > 500;
Это SQL-выражение представляет собой запрос, который на естественном языке выглядит приблизительно так:
ВЫБРАТЬ СТОЛБЦЫ имя, Адрес ИЗ ТАБЛИЦЫ клиенты ГДЕ Сумма_заказа > 500;
Здесь из таблицы клиенты выбираются записи, в которых значение столбца Сумма_заказа превышает 500. При этом в результатной таблице будут представлены только два столбца таблицы Клиенты: Имя и Адрес.
Столбец Сумма_заказа, имеющийся в исходной таблице, в данном случае не выводится (отсутствует в результирующей таблице). Впрочем, если бы вам потребовалось увидеть конкретные суммы, превышающие 500, то для этого было бы достаточно указать в списке столбцов, следующем за оператором SELECT, еще и столбец Сумма_заказа.

Рис. 2. Результат запроса "WHERE Сумма_заказа > 500"
Следующее SQL-выражение создает виртуальную таблицу, содержащую три Столбца: Регион, Имя и Адрес. Из таблицы Клиенты выбираются только те записи, в которых Сумма__заказа превышает 500, и они группируются по значениям столбцов Регион, Имя и Адрес. Это означает, что в результатной таблице записи, имеющие одинаковые значения в столбце Регион, будут расположены рядом друг с другом. Наконец, все записи в результатной таблице упорядочиваются по значениям столбца Имя (рис. 3).
SELECT Регион, Имя, Адрес FROM Клиенты
WHERE Сумма_заказа > 500
GROUP BY Регион, Имя, Адрес
ORDER BY Имя;

Рис. 3. Результат запроса "WHERE Сумма_заказа > 500"
с группировкой "GROUP BY Регион, Имя, Адрес" и сортировкой "ORDER BY Имя"
Оператор выборки записей из исходной таблицы может соседствовать с другими SQL-операторами.
Оператор WHERE
Условия поиска в операторе WHERE (где) являются логическими выражениями, т. е. принимающими одно из двух возможных значений - true (ИСТИНА) или false (ЛОЖЬ). Например, выражение Сумма_заказа > 500 является истинным (имеет значение true), если в текущей записи таблицы значение столбца Сумма_заказа превышает 500. В противном случае это выражение ложно (имеет значение false). Одно и то же логическое выражение может быть истинным для одних записей и ложным для других. Вообще говоря, в SQL логические выражения могут принимать еще и неопределенное значение. Это происходит тогда, когда в выражении некоторые элементы имеют значение NULL. Тaким образом, в SQL мы имеем дело не с классической двузначной, а с трехзначной логикой.
Выражение, следующее за оператором WHERE, возвращает одно из трех значений: true, false или NULL. При выполнении запроса (SQL-выражения) логическое выражение WHERE применяется ко всем записям исходной таблицы. Если оно истинно для данной записи исходной Таблицы, то эта запись выбирается и будет представлена в результатной таблице; в противном случае запись не попадет в результатную таблицу.
При составлении логических выражений используются специальные ключевые слова и символы операций сравнения, которые называют предикатами . Предикат впервые появился в SQL: 1999. Например, в выражении Сумма_заказа > 500 применен предикат сравнения (>).
Выражения с оператором WHERE используются не только при выборке данных (т.е. с оператором SELECT), но и при вставке, модификации и удалении записей. Таким образом, материал данного раздела имеет значение, выходящее за границы рассматриваемой темы о выборке данных.
Наиболее часто используются предикаты сравнения , такие как (=), (<),(>), (<>), (<=) и (>=). Однако имеются и другие. Далее приведен список всех предикатов:
· предикаты сравнения:
(=) - равно, (<) - меньше, (>) - больше, (< >) – не равно,
(<=) – меньше или равно (не больше), (>=) - больше или равно (не меньше);
· LIKE, NOT LIKE;
· ALL, SOME, ANY;
Примечание
В обычных процедурных языках программирования перечисленные символы сравнения называются операторами сравнения, а не предикатами, но как бы мы ни называли все, что связано с символами сравнения, суть остается неизменной.
Предикат BETWEEN (между) позволяет задать выражение проверки вхождения какого-либо значения в диапазон, определяемый граничными значениями. Например:
WHERE Сумма_заказа BETWEEN 100 AND 750
Здесь ключевое слово AND представляет собой логический союз И. Граничные значения (в примере это 100 и 750) входят в диапазон. Причем первое граничное значение должно быть не больше второго.
Эквивалентным приведенному является выражение с предикатами сравнения:
WHERE Сумма_заказа >= 100 AND Сумма_заказа <= 750
Кроме данных числового типа, в выражениях с BEETWEEN можно использовать данные следующих типов: символьные, битовые, даты-времени. Так например, чтобы выбрать записи, в которых имена клиентов находятся в диапазоне от А до Ж, можно использовать такое выражение:
SELECT Имя, Адрес FROM Клиенты
WHERE Имя BETWEEN "А" AND " Ж" ;
IN и NOT IN
Предикаты IN (в) и NOT IN (не в) применяются для проверки вхождения какого-либо значения в заданный список значений. Например, для выборки записей о клиентах из некоторых регионов можно использовать такое выражение:
SELECT Имя, Адрес FROM Клиенты
WHERE Регион IN ("Северо-запад", "Ставропольский край",
"Иркутская область");
Если требуется получить данные о всех клиентах не из Москвы и Северо-Запада, то можно использовать предикат NOT IN:
SELECT Имя, Адрес FROM Клиенты
WHERE Регион NOT IN ("Москва", "Санкт-Петербург");
LIKE и NOT LIKE
Предикаты LIKE (похожий) и NOT LIKE (не похожий) применяются для проверки частичного соответствия символьных строк. Например, столбец Телефон в некоторой таблице содержит полные номера телефонов, а вам требуется выбрать лишь те записи, в которых номера телефонов начинаются с 348 или содержат такое сочетание цифр.
Критерий частичного соответствия задается с помощью двух символов-масок: знака процента (%) и подчеркивания (_). Знак процента означает любой набор символов, в том числе и пустой, а символ подчеркивания - любой одиночный символ. Например, чтобы выбрать записи о клиентах, у которых номера телефонов начинаются с 348, можно использовать такое выражение:
WHERE Телефон LIKE "348%";
Допустим, столбец Адрес содержит полный почтовый адрес (индекс, название города, улицы и т. д.). Если вам требуется выбрать записи о клиентах, проживающих в Санкт-Петербурге, то для этого подойдет следующее выражение:
SELECT Имя, Адрес, Телефон FROM Клиенты
WHERE Адрес LIKE "%Санкт-Петербург%";
Если вы хотите исключить всех клиентов, проживающих в Москве, то воспользуйтесь таким выражением:
SELECT Имя, Адрес, Телефон FROM Клиенты
WHERE Адрес NOT LIKE "%Москва%";
Возможно, вам потребуется выбрать записи, срдержащие символы процента и/или подчеркивания. Тогда необходимо, чтобы такие символы воспринимались интерпретатором SQL не как символы-маски. Чтобы знак процента или подчеркивания воспринимался буквально, перед ним необходимо указать специальный управляющий символ. Этот символ можно определить произвольно, лишь бы он не встречался в качестве элемента данных. В следующем примере показано, как это можно сделать:
SELECT- Имя, Адрес, Процент_скидки FROM Клиенты
WHERE Процент_скидки LIKE "20#%"
Здесь за ключевым словом ESCAPE указывается символ, который используется в качестве управляющего. Таким же способом можно отключить и сам управляющий символ.
Предикат IS NULL применяется для выявления записей, в которых тот или иной столбец не имеет значения. Например, для получения записей о клиентах, для которых не указан адрес, можно использовать следующее выражение:
WHERE Адрес IS NULL;
Для получения записей, в которых столбец Адрес содержит некоторые определенные значения (т. е. отличные от NULL), можно использовать аналогичное выражение, но с логическим оператором NOT (не):
SELECT Имя, Адрес, Регион FROM Клиенты
WHERE Адрес IS NOT NULL;
Не следует использовать предикаты сравнения с NULL, такие как Адрес = NULL.
В рамках данной статьи, я расскажу вам самые азы баз данных и приведу примеры sql-запросов для начинающих .
Когда человек впервые начинает читать обзоры про базы данных, то его голова просто разрывается от огромной массы технических терминов. Все эти первичные и вторичные ключи, таблицы, связи, процедуры, представления, индексы, условия, подзапросы, колонки, типы данных и прочее. И все это "как бы" необходимо учитывать. Как говорится, "А-а-а-а-а".
Однако, в этом и состоит одна из самых больших ошибок - читать термины, а не понимать их суть . Поэтому, многие из таких любознательных и нетерпеливых либо бросают это дело, либо вскользь осваивают материал и потом пишут невесть что. Изучать базу данных нужно с самого простого - с основы. И уже только затем остальные возможности.
Прочитав этот обзор, вы усами убедитесь, что никаких сверх сложных тайн в базах данных нет, сложности лишь касаются отдельных технических аспектов, позволяющих, к примеру, оптимизировать скорость и потребляемую оперативную память.
Примечание : Материал предназначен для начинающих, но часть вещей может быть полезна и остальным.
Основа любой базы данных - таблицы и 4 типа запросов
Основой любой базы данных являются всего две вещи - это таблицы и 4 типа запросов. Именно с них и началось. Все эти сложности, которые описываются тысячами веб-сайтов в Интернете, появились уже после них и применяются к этим азам.
Первым делом, рассмотрим что такое таблица . Хоть раз, но каждый открывал эксельный файл или электронную таблицу OpenOffice (см. обзор офисных пакетов). Так вот это, по сути, и есть база данных. У вас есть колонки и строки, в пересечении которых вы заполняете данные (числа, текст, даты и прочее).
Однако, тут есть важный момент - если эксель позволяет произвольно вставлять данные в любую ячейку, то существующие базы данных имеют некоторые ограничения.
1. Каждая колонка имеет уникальное некое имя (аналогично A, B, C).
2. В каждой колонке могут располагаться данные только одного типа. К примеру, в любой ячейке колонки B только числа, в колонке C только текст, в колонке F только даты.
3. Количество колонок фиксировано и исчислимо. Простыми словами, в экселе вы можете в любой момент вставить некие данные в ячейку рядом с определенными колонками. В базах данных же, подобное требует, что бы вы сначала добавили колонку с именем и определили ее тип, а только лишь потом редактировали данные.
4. Единицей измерения таблицы принято считать не отдельную ячейку, а каждую строку. К примеру, если у вас в таблице три колонки "Имя (Name) / День рождения (Date) / Возраст (Age)", то единицей измерения считается "Вася / 12.12.2012 / 7", а не какое-либо отдельное значение. Конечно, редактировать или просматривать отдельные ячейки этой строки можно, но добавлять данные в таблицу можно только построчно.
5. Существует специальное значение NULL, которое обозначает отсутствие данных в ячейке. Понять суть можно из следующего момента - далеко не у всех типов данных можно установить такое значение, которое можно было бы считать отсутствием данных. К примеру, для текста отсутствие данных можно как-то сравнить с пустой строкой (хотя и это не всегда корректно), а вот для чисел такого значения просто не существует (0 это число; к примеру, "осталось 0 яблок"). Поэтому и было введено специальное значение NULL.
Пример таблицы somedata:
Рассмотрим основные 4 типа запросов . Не сложно догадаться, что подобную таблицу хотелось бы каким-то образом составлять под конкретные задачи, а так же получать отфильтрованные данные. Просто представьте, что в таблице выше не 3 строки, а целых 10 000. Найти что-либо или подкорректировать будет весьма проблематично. Именно поэтому и были введены следующие 4 типа запросов:
1. Вставка (insert) - позволяет вставлять в таблицу единицы измерения, то есть строки.
2. Удаление (delete) - позволяет удалять из таблицы строки данных.
3. Обновление (update) - позволяет изменять отдельные ячейки строк.
4. Выборка (select) - позволяет из данных таблицы получать произвольного вида подтаблицы с необходимыми результатами, которые так же называют выборками.
Рассмотрим все типы более подробно.
Но, перед этим, хотелось бы отметить, что будет использован синтаксис для базы данных MySQL. Однако, для азов это не так критично, так как приведенные примеры если и будут отличаться в разных базах данных, то весьма незначительно.
Запрос вставки (insert)
Запрос вставки строится следующим образом:
insert into table (col1, col2, ..., colN) values (val11, val12, ..., val1N), (val21, val22, ..., val2N), ..., (valM1, valM2, ..., valMN);
где insert into - это начало запроса, table (col1, col2, ..., colN) - это названия колонок в нужном порядке (сделано для удобства), values - указывает, что далее будут указаны строки для вставки, (val11, val12, ..., val1N), (val21, val22, ..., val2N), ..., (valM1, valM2, ..., valMN) - это конкретные значения для вставки (в соответствующем порядке с колонками). Важно, что после каждого sql-запроса необходимо ставить точку с запятой. Это позволяет отделять одни запросы от других.
К примеру, если бы потребовалось добавить две строки в таблицу из примера somedate, то sql-запрос выглядел бы так:
insert into somedata (Name, Age, Date) values ("Коля", 10, "04.05.2009"), ("Анастасия", 22, "12.02.1997");
Это строчки появились бы в конце таблицы. Конечно, в реальных базах данных, размещение строчек может сильно зависеть от применяемых механизмов, однако по умолчанию это так.
Запрос для удаления данных (delete)
SQL-запрос для удаления данных строится следующим образом:
где delete from - это начало запроса, table - это конкретное название таблицы, where - указывает, что далее будут указаны фильтры строк, которые необходимо удалить, clause - это сами фильтры для выборки строк. После sql-запроса ставится точка с запятой.
Важно отметить, что фильтр может быть весьма сложным и состоять из большого количества условий. Для его составления используются три операнда - and (И) , or (ИЛИ) и скобки (для отделения сложных выражений) . Логика здесь аналогична самой простой математики.
Примечание
К примеру, представим, что вам необходимо удалить все строки, где возраст больше 1 и меньше 5, или же строки, в которых указывается имя Масяня. Тогда запрос выглядел бы так:
Если разбирать логику, то этот запрос говорит базе данных, чтобы она проверила каждую строчку таблицы somedate и если строка удовлетворяет условиям, то ее необходимо удалить.
Запрос обновления данных (update)
Запрос обновления данных строится следующим образом:
где update - это начало sql-запроса, table - это конкретное имя таблицы, set - обозначает, что далее будет список требуемых изменений, col1 = val1, col2 = val2, ..., colN = valN - это перечисление через запятую колонок с присваиваемыми им значениями, where - указывает, что далее будут перечислены условия отбора, clause - условие фильтра (аналогично delete). Запрос так же заканчивается точкой с запятой.
Примечание : Важно отметить, что часть where с clause являются необязательными. То есть, если фильтр не требуется, то их можно не писать. Однако, если фильтр нужен, то обе составляющих необходимо использовать в запросе.
К примеру, если необходимо не удалить все строки из примера ранее, а указать для всех этих строк дату рождения 31.12.2222 и возраст -203, то sql-запрос выглядел бы так:
Обратите внимание, что поля Age и Date изменяются только после проверки условий фильтра. Это важно, так как запрос позволяет использовать текущие значения колонок при фильтрации (иначе бы могли возникать несоответствия).
Запрос для выборки данных (select)
Это, пожалуй, один из самых часто используемых типов sql-запросов (ведь данные составляются не для хранения, а для их использования) и поэтому у него имеется масса дополнительных возможностей (сортировка, группировка и так далее; о них читайте в прочих обзорах, в рамках этого обзора они не столь важны).
Строится данный запрос следующим образом:
где select - это начало запроса, col1, col2, ..., colN - это перечисление колонок, которые необходимо отобразить (важно знать, что если требуются все колонки таблицы, то вместо перечисления можно указывать просто символ звездочки * , что очень удобно, особенно, если структура таблицы постоянно корректируется или же заранее не известны все доступные колонки, кроме тех, что в фильтре), from - обозначает, что далее будет указано имя таблицы, where - обозначает, что далее будет указан фильтр, clause - сам фильтр (аналогично delete и update). После sql-запроса ставится точка с запятой.
Примечание : Важно отметить, что часть where с clause являются необязательными. То есть, если фильтр не требуется, то их можно не писать. Однако, если фильтр нужен, то обе составляющих необходимо использовать в запросе.
Рассмотрим пример. Допустим, нам необходимо получить возраст и имя всех тех, чье день рождение было до 1-го января 1999 года. Тогда sql-запрос будет выглядеть так:
Обратите внимание, что порядок колонок после select может быть произвольным, что позволяет получать удобные для восприятия подтаблицы данных (выборки).
Послесловие
Стоит знать, что каждая из баз данных позволяет использовать рассмотренные sql-запросы с расширенными возможностями. К примеру, одновременное удаление из нескольких таблиц или же вставка строк с использованием запросов выборки. Поэтому, если у вас возникает необходимость в чем-то специфическом, то стоит более подробно изучать возможности каждой базы данных.

SQL - это аббревиатура выражения Structured Query Language (язык структурированных запросов). SQL основывается на реляционной алгебре и специально разработан для взаимодействия с реляционными базами данных.
SQL является, прежде всего, информационно-логическим языком, предназначенным для описания хранимых данных, их извлечения и модификации. SQL не является языком программирования. Вместе с тем конкретные реализации языка, как правило, включают различные процедурные расширения.
Язык SQL представляет собой совокупность операторов, которые можно разделить на четыре группы:
- DDL (Data Definition Language) - операторы определения данных
- DML (Data Manipulation Language) - операторы манипуляции данными
- DCL (Data Control Language) - операторы определения доступа к данным
- TCL (Transaction Control Language) - операторы управления транзакциями
SQL является стандартизированным языком. Стандартный SQL поддерживается комитетом стандартов ANSI (Американский национальный институт стандартов), и соответственно называется ANSI SQL.
Многие разработчики СУБД расширили возможности SQL, введя в язык дополнительные операторы или инструкции. Эти расширения необходимы для выполнения дополнительных функций или для упрощения выполнения определенных операций. И хотя часто они очень полезны, эти расширения привязаны к определенной СУБД и редко поддерживаются более чем одним разработчиком. Все крупные СУБД и даже те, у которых есть собственные расширения, поддерживают ANSI SQL (в большей или меньшей степени). Отдельные же реализации носят собственные имена (PL-SQL, Transact-SQL и т.д.). Transact-SQL (T-SQL) – реализация языка SQL корпорации Microsoft, используемая, в частности, и в SQL Server.
Запросы на выборку данных (оператор SELECT)
SELECT – наиболее часто используемый SQL оператор. Он предназначен для выборки информации из таблиц. Чтобы при помощи оператора SELECT извлечь данные из таблицы, нужно указать как минимум две вещи - что вы хотите выбрать и откуда.
Выборка отдельных столбцов
SELECT
FROM Product
В приведенном выше операторе используется оператор SELECT для выборки одного столбца под названием Description из таблицы Product. Искомое имя столбца указывается сразу после ключевого слова SELECT, а ключевое слово FROM указывает на имя таблицы, из которой выбираются данные.
Для создания и тестирования данного запроса в Management Studio выполните следующие шаги:
Выборка нескольких столбцов
Для выборки из таблицы нескольких столбцов используется тот же оператор SELECT. Отличие состоит в том, что после ключевого слова SELECT необходимо через запятую указать несколько имен столбцов.
SELECT , InStock
FROM Product
Выборка всех столбцов
Помимо возможности осуществлять выборку определенных столбцов (одного или нескольких), при помощи оператора SELECT можно запросить все столбцы, не перечисляя каждый из них. Для этого вместо имен столбцов вставляется групповой символ “звездочка” (*). Это делается следующим образом.
SELECT *
FROM Product
Сортировка данных
В результате выполнения запроса на выборку данные выводятся в том порядке, в котором они находятся в таблице. Для точной сортировки выбранных при помощи оператора SELECT данных используется предложение ORDER BY. В этом предложении указывается имя одного или нескольких столбцов, по которым необходимо отсортировать результаты. Взгляните на следующий пример.
FROM Product
ORDER BY InStock
Это выражение идентично предыдущему, за исключением предложения ORDER BY, которое указывает СУБД отсортировать данные по возрастанию значений столбца InStock.
Сортировка по нескольким столбцам
Чтобы осуществить сортировку по нескольким столбцам, просто укажите их имена через запятую. В следующем коде выбираются три столбца, а результат сортируется по двум из них - сначала по количеству, а потом по названию.
SELECT IdProd, , InStock
FROM Product
ORDER BY InStock,
Важно понимать, что при сортировке по нескольким столбцам порядок сортировки будет таким, который указан в запросе. Другими словами, в примере, приведенном выше, продукция сортируется по столбцу Description, только если существует несколько строк с одинаковыми значениями InStock. Если никакие значения столбца InStock не совпадают, данные по столбцу Description сортироваться не будут.
Указание направления сортировки
В предложении ORDER BY можно также использовать порядок сортировки по убыванию. Для этого необходимо указать ключевое слово DESC. В следующем примере продукция сортируется по количеству в убывающем порядке плюс по названию продукта.
SELECT IdProd, , InStock
FROM Product
ORDER BY InStock DESC ,
Ключевое слово DESC применяется только к тому столбцу, после которого оно указано. В предыдущем примере ключевое слово DESC было указано для столбца InStock, но не для Description. Таким образом, столбец InStock отсортирован в порядке убывания, а столбец Description в возрастающем порядке (принятым по умолчанию).
Вы новичок в программировании или же просто раньше избегали изучения SQL? Тогда вы попали по нужному адресу, так как любой разработчик в конце-концов сталкивается с необходимостью знать этот язык запросов. Пусть вы и не будете главным дизайнером баз данных, но работы с ними избежать практически невозможно. Я надеюсь этот краткий обзор синтаксиса основных SQL-запросов поможет заинтересованному разработчику и любому, кому это понадобится.
Что такое база данных SQL?
Структурированный язык запросов (Structured Query Language) – стандарт коммуникации с базой данных, который поддержан ANSI. Самая последняя версия – SQL-99, хотя новый стандарт SQL-200n уже находится в разработке. Большинство баз данных твердо придерживается стандарта ANSI-92. Было много обсуждений по поводу введения более современных стандартов, но изготовители коммерческих баз данных отклоняются от этого, развивая свои новые концепции манипуляции хранимыми данными. Почти каждая отдельная база данных использует некоторый уникальный набор синтаксиса, хоть и очень сильно подобного стандарту ANSI. В большинстве случаев, этот синтаксис является расширением базового стандарта, хотя бывают случаи, когда такой синтаксис приводит к различным результатам для разных баз данных. Всегда неплохой идеей будет просмотр документации к базе данных, особенно, если получаются неожиданные результаты.
Если вы впервые встречаетесь с SQL, то необходимо ознакомиться с основными концепциями, которые нужно понять.
В общих терминах, «SQL база данных» является общим названием для реляционной системы управления базами данных (РСУБД). Для некоторых систем, «база данных» также относится к группе таблиц, данных, конфигурационной информации, которые являются неотъемлемо отдельной частью от других, подобных конструкций. В этом случае, каждая инсталляция SQL базы данных может состоять из нескольких баз данных. В других системах, они упомянуты как таблицы.
Таблица – конструкция базы данных, которая состоит из столбцов, содержащих строки данных. Обычно таблицы созданы для того, чтобы содержать связанную информацию. В пределах той же самой базы данных могут быть созданы несколько таблиц.
Каждый столбец представляет собой атрибут или совокупность атрибутов объектов, например идентификационные номера служащих, рост, цвет машин и т.п. Часто в отношении столбца используется термин поле с указанием имени, например «в поле Name». Поле строки является минимальным элементом таблицы. Каждый столбец в таблице имеет определенное имя, тип данных и размер. Имена столбцов должны быть уникальны в пределах таблицы.
Каждая строка (или запись) представляет собой совокупность атрибутов конкретного объекта, например, в строке может содержаться идентификационный номер служащего, размер его зарплаты, год его рождения и т.д. Строки таблиц не имеют названий. Чтобы обратиться к конкретной строке, пользователю необходимо указать какой-то атрибут (или набор атрибутов), уникально ее идентифицирующий.
Одной из важнейших операций, которые выполняются при работе с данными, является выборка хранящейся в базе данных информации. Для этого пользователь должен выполнить запрос (query).
Теперь давайте рассмотрим основные типы запросов к базе данных, которые сосредоточены на манипуляции данными в пределах базы. Для наших целей, все примеры приведены в стандартном SQL, дабы соответствовать любой среде.
Типы запросов данных
Есть четыре основных типа запросов данных в SQL, которые относятся к так называемому языку манипулирования данными (Data Manipulation Language или DML):
SELECT
– выбрать строки из таблиц;
INSERT
– добавить строки в таблицу;
UPDATE
– изменить строки в таблице;
DELETE
– удалить строки в таблице;
Каждый из этих запросов имеет различные операторы и функции, которые используются для того, чтобы произвести какие-то действия с данными. Запрос SELECT имеет самое большое количество опций. Существуют также дополнительные типы запросов, используемых вместе с SELECT, типа JOIN и UNION. Но пока, мы сосредоточимся только на основных запросах.
Использование запроса SELECT для выборки нужных данных
Чтобы получить информацию, хранящуюся в базе данных используется запрос SELECT. Базовое действие этого запроса ограничено одной таблицей, хотя существуют конструкции, обеспечивающие выборку с нескольких таблиц одновременно. Для того, чтобы получить все строки данных для специфических столбцов, используется запрос такого вида:
SELECT column1, column2 FROM table_name;
Также, можно получить все столбцы из таблицы, используя подстановочный знак «*»:
SELECT * FROM table_name;
Это может быть полезно в том случае, когда вы собираетесь выбрать данные с определенным условием WHERE. Следующий запрос возвратит все столбцы со всех строк, где «column1» содержит значение «3»:
SELECT * FROM table_name WHERE column1=3;
Кроме «=» (равно), существуют следующие условные операторы:
Условные операторы:
= Равно
<>
Не равно
>
Больше
<
Меньше
>=
Больше или равно
<=
Меньше или равно
Дополнительно можно использовать условия BITWEEN и LIKE для сравнения с условием WHERE, а так же комбинации операторов AND и OR.
SELECT * FROM table_name WHERE ((Age >= 18) AND (LastName BETWEEN ‘Иванов’ AND ‘Сидоров’)) OR Company LIKE ‘%Motorola%’;
Что в переводе на русский язык означает: выбрать все столбцы из таблицы table_name, где значение столбца age больше или равно 18, а также значение столбца LastName находится в алфавитном промежутке от Иванов до Сидоров включительно, или же значением столбца Company является Motorola.
Использование запроса INSERT для вставки новых данных
Запрос INSERT используется для создания новой строки данных. Для обновления уже существующих данных или пустых полей строки нужно использовать запрос UPDATE.
Примерный синтаксис запроса INSERT:
INSERT INTO table_name (column1, column2, column3) VALUES (‘data1’, ‘data2’, ‘data3’);
Если вы собираетесь вставлять все значения в порядке, в котором находятся столбцы таблицы, то можно и не указывать имена столбцов, хотя для удобочитаемости это предпочтительнее. Кроме того, если вы перечисляете столбцы, необязательно указывать их по порядку нахождения в базе данных, пока значения, которые вы вводите, соответсвуют этому порядку. Вы не должны перечислять столбцы, в которые не вводится информация.
Изменяется уже существующая информация в базе данных очень похожим образом.
Запрос UPDATE и условие WHERE
UPDATE используется для того, чтобы изменить существующие значения или освободить поле в строке, поэтому новые значения должны соответствовать существующему типу данных и обеспечивать приемлемые значения. Если вы не хотите изменить значения во всех строках, то нужно использовать условие WHERE.
UPDATE table_name SET column1 = ‘data1’, column2 = ‘data2’ WHERE column3 = ‘data3’;
Вы можете использовать WHERE для любого столбца, включая тот, который хотите изменить. Это используется когда необходимо заменить одно определенное значение на другое.
UPDATE table_name SET FirstName = ‘Василий’ WHERE FirstName = ‘Василий’ AND LastName = ‘Пупкин’;
Будьте осторожны! Запрос DELETE удаляет целые строки
Запрос DELETE полность удаляет строку из базы данных. Если вы хотите удалить одно единственное поле, то нужно использовать запрос UPDATE и установить для этого поля значение, которое будет являться аналогом NULL в вашей программе. Будьте внимательны, и ограничивайте ваш запрос DELETE условием WHERE, иначе вы можете потерять все содержимое таблицы.
DELETE FROM table_name WHERE column1 = ‘data1’;
Как только строка была удалена из вашей базы данных, она не подлежит восстановлению, поэтому желательно иметь столбец по имени «IsActive», или что-то типа того, который вы можете изменить на ноль, что будет указывать на блокировку представления данных из этой строки.
Теперь вы знаете основы SQL запросов
SQL – язык баз данных, и мы рассмотрели наиболее важные и базовые команды, используемые в запросах данных. Множество основных концепций не были затронуты (SUM и COUNT например), но те немногие команды, которые удалось перечислить выше, должны побудить вас к активным действиям и более глубокому изучению замечательного языка запросов под именем SQL.